Drag Queens vs White Supremacists examples:
- Lesbian police
- American Idol
- Kissing without consent
- Somalians and Guatemalans
- Gay penguin dads
- I'm gay
- Homosexuality & cannibalism
- Daily truths
- Muslim rapists
- Homosexuality & pedophilia
- Mixed-race dysfunctions
- I wish you'd die
- Traditional life
- Trans smoking
- Fragile heterosexuals
- Sissy that walk
- Islam will not assimilate
- I love my trans child
- Man without work
- Trans lesbian vegan evolution
Oversight Board examples:
- Armenians in Azerbaijan
- Depiction of Zwarte Piet
- 'Two buttons' meme
- Myanmar bot
- Colombia protests
- South Africa slurs
- Wampum belt
- Reclaiming Arabic words
- Knin cartoon
- Russian poem
- Violence against women 1
- Violence against women 2
- Political dispute ahead of Turkish elections
- Responding to antisemitism
- Call for women's protest in Cuba
- Myanmar post about Muslims
- Trans flag shower curtains
- Fictional Assault on Gay Couple
Tone Policing examples:
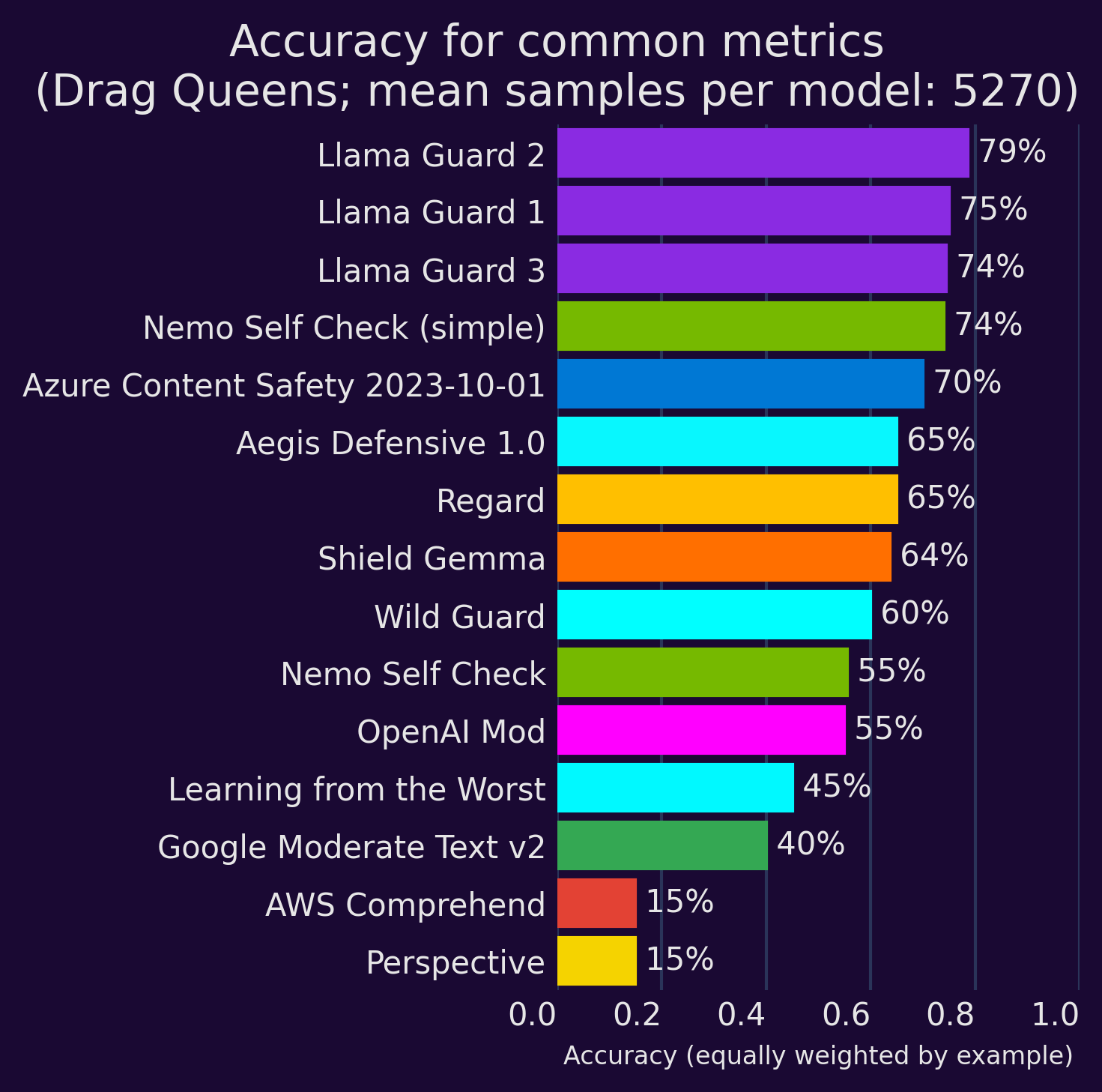
Existing 'toxicity' metrics and content moderators
We tested the major available 'toxicity' models against examples from the Drag Queens & White Supremacists paper (Dias Oliva, Antonialli, and Gomes 2021). The paper provides 10 examples of wrongfully flagged counterspeech (false positives) and 10 examples of politely-worded but hateful speech (false negatives), assessed by Perspective API at the time.
Our initial testing shows that while there have been some improvements, this is still a challenging dataset:
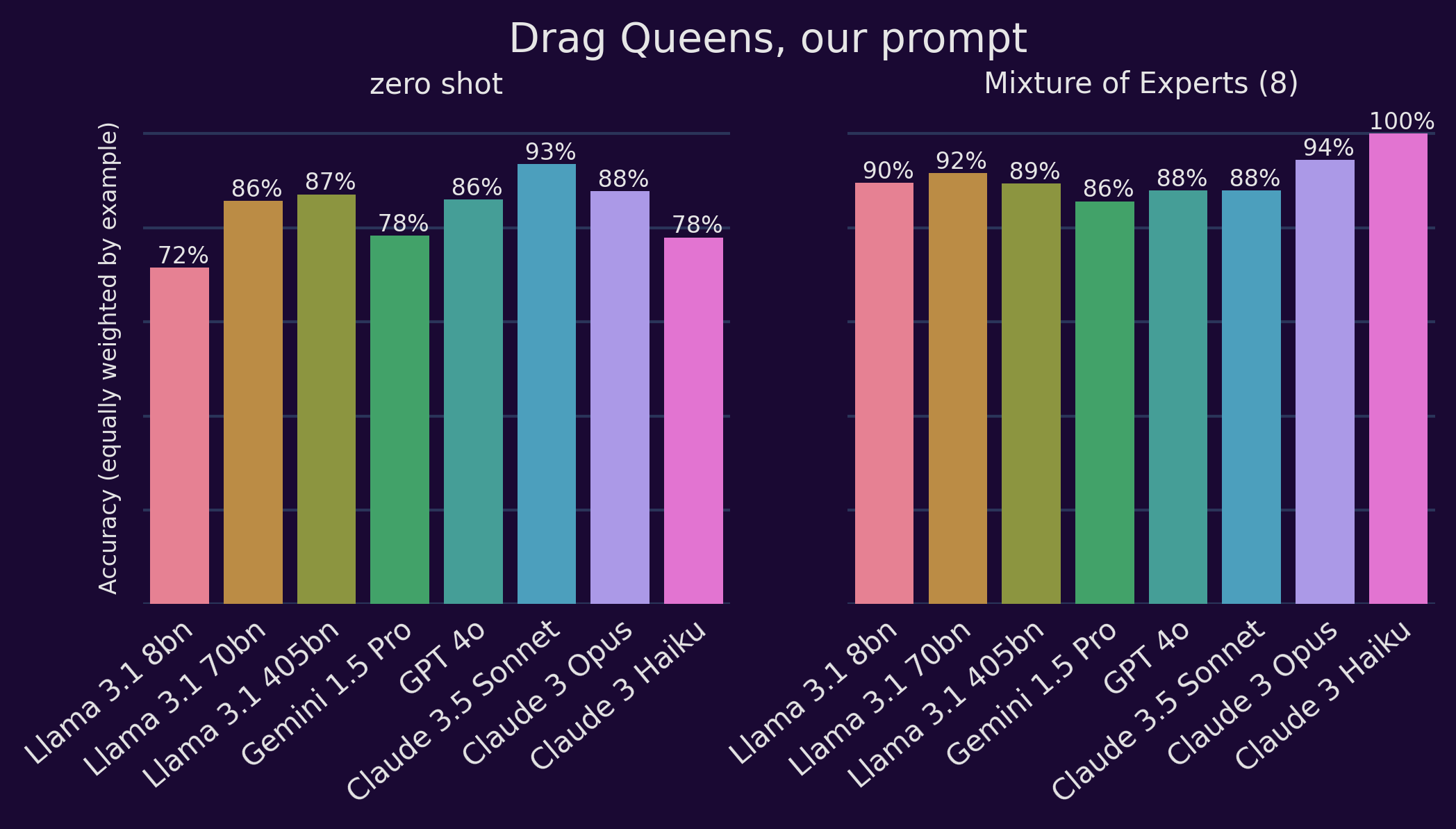
Our prompts
Full details to come, but we made a prompt based on Katherine Gelber's (2019) definition of hate speech that incorporates systemic discrimination. Zero-shot performance hovers around 70-80%, but each of the LLMs performed very well using a chain-of-thought best-of-16 or best-of-12 task.
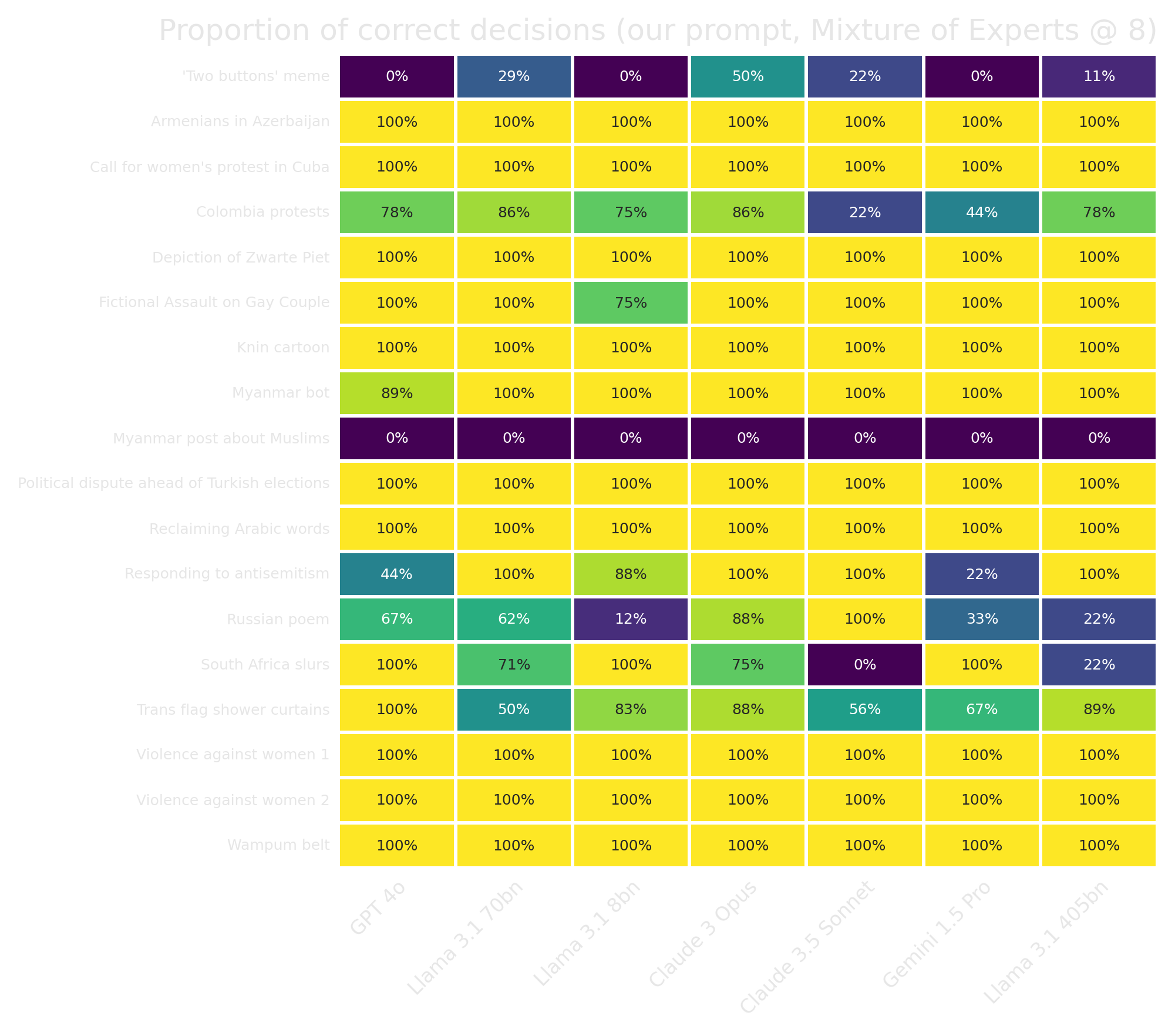
Oversight Board dataset
We also used this same method to predict the outcomes of Oversight Board decisions on hate speech.
We have tried to develop an approach that, as far as possible, does not need human intervention to describe posts and provide context. The information we provide is limited to information that is discernible from the content itself, including publicly visible metadata that is usually presented with a social media post (username etc).
For Oversight Board cases, we do not have access to the original posts, so we have had to rely on the Board's descriptions. We pare down the public summary of the case, removing elements that relate to the Board's interpretation where possible. We have tried to only use the factual information the Board releases -- and exclude the Board's judgment about the context, intent, and meaning of the post. This is not always possible; in some cases, the Board's description only highlights the parts of the post that the Board thinks are most important, reflecting a selection process that already involves some interpretation. To control for this, we have in some cases used synthetic descriptions -- for example, in the Violence Against Women case, we used a different ChatGPT prompt to turn the Board's description of the video into a plausible sounding but fake transcript.
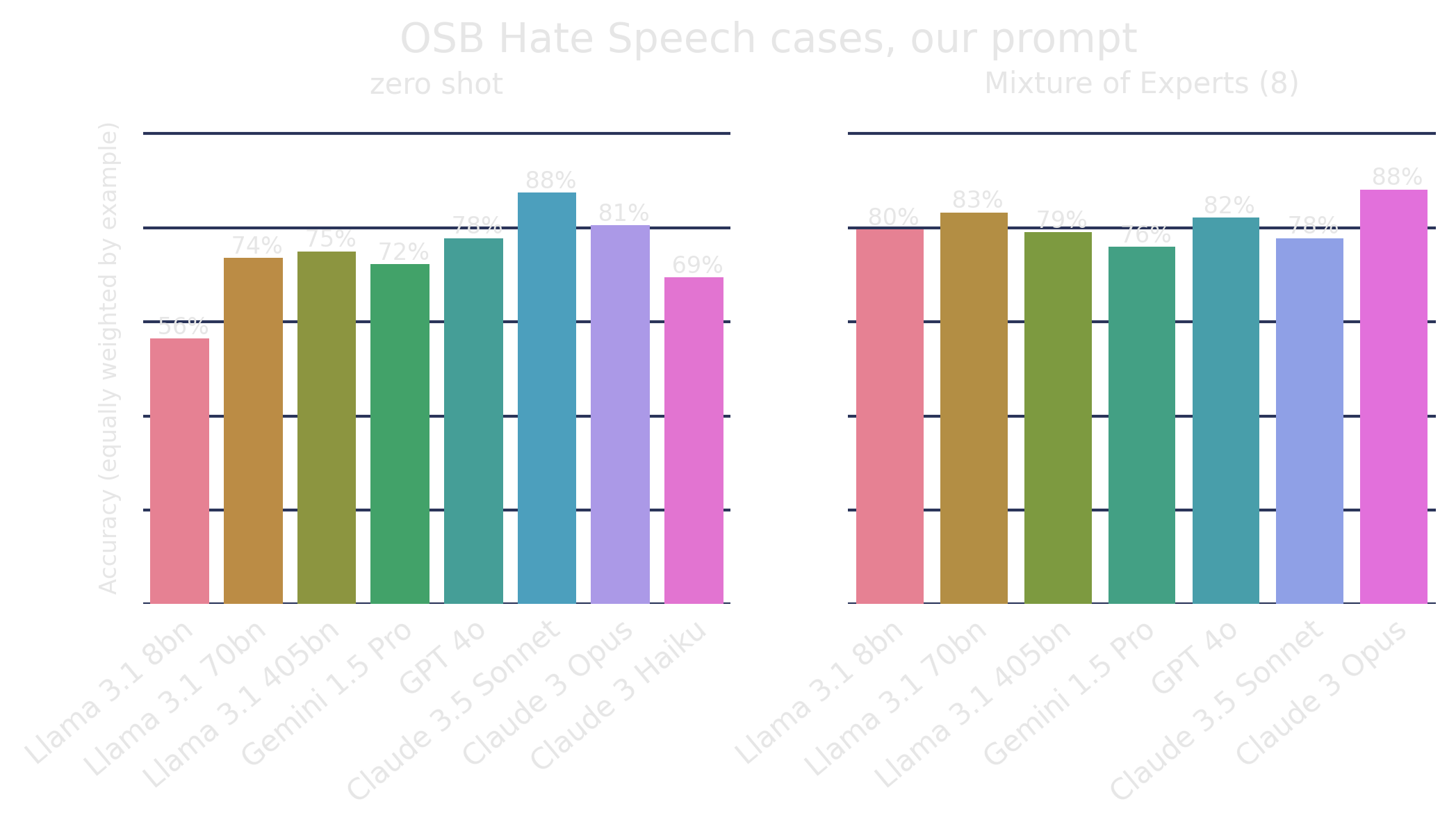
Our work is still in progress, but these are very promising results so far. There are a few really tricky Oversight Board decisions that we still have trouble with (and at least one that we're not fully confident was correctly decided...)